来源:DeepTech深科技
无需打字、无需搜索表情,只需对着手机微笑,就能发出微笑表情包。
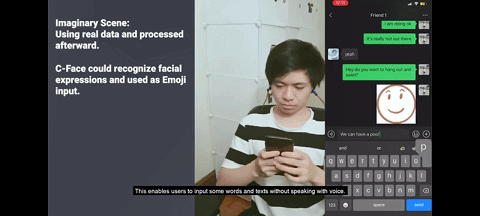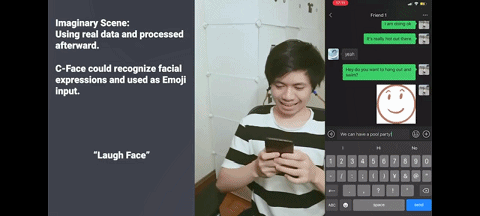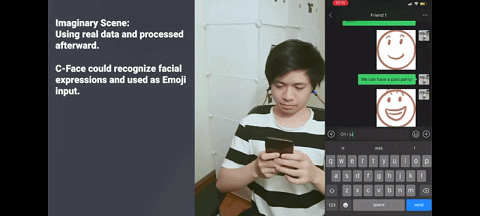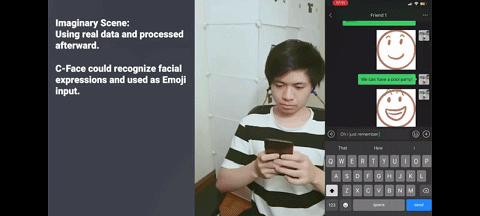
同样的,对着手机皱眉,就能发出皱眉表情包。
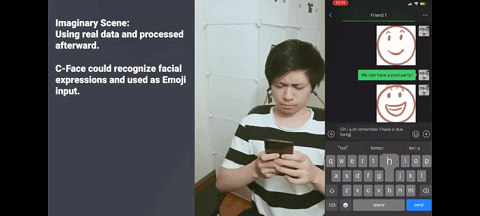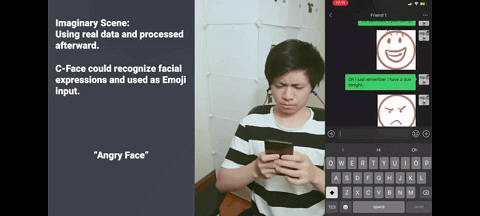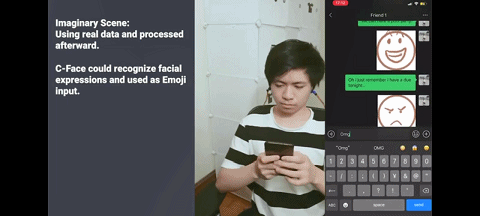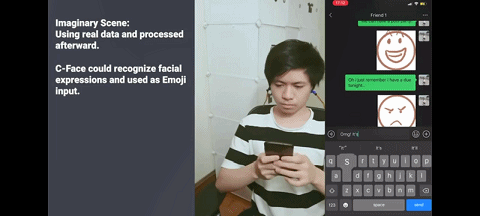
以上功能来自一款名为 C-Face 耳机的设备,它诞生于康奈尔大学华人科学家张铖的 SciFi 实验室。他近日以通讯作者身份在 UIST 2020(User Interface Software and Technology)会议上发表了这项研究,论文名为《即使戴着口罩耳机也可以跟踪面部表情》(Earphone tracks facial expressions, even with a face mask)。

图
除张铖之外,论文第一作者还有来自北京大学、目前在康奈尔大学访问的本科生陈拓潮。
论文表示,该耳机可通过观察脸颊轮廓,来连续跟踪面部表情,并能把表情转换为表情符号、或无声语音命令。DeepTech 联系到张铖,并就该耳机和其进行了深入交流。
他表示,C-Face 耳机是实验室系列研究的其中一款设备。该系列研究主要探索信息的获知,如果缺乏信息,计算机就很难理解人类动机和行为。而 SciFi 实验室的长期工作,是致力于提升人机交流,但是第一步,计算机需要获取到信息。
摄像头是获取信息的最常用手段之一,比如在室内外布置摄像头,并且摄像头必须没有遮挡,这就导致传统的 “摄像头方法” 会在某些场景中失灵。比如,在获取脸部表情时,是用摄像头直接 “捕捉” 人脸,但用户在外面时,不可能时刻脸部对着摄像头。
而本次的 C-Face 耳机,正是一款可用于实时获取脸部信息的耳机。其原理是,由于人脸有很多肌肉,肌肉之间相互连接,脸部在做不同表情时,其他肌肉也会被牵动,嘴巴、眼睛和眉毛的位置与形状也会发生变化。基于此,经该实验室的设计后,耳机可通过比较容易捕捉到的肌肉变化来推测出面部表情。

图 不戴口罩时戴着耳机做表情
由于新冠疫情的影响,研究人员只能在 9 名参与者的情况下测试耳机。尽管如此,表情符号的识别准确度仍然超过 88%,面部提示的准确度超过 85%。
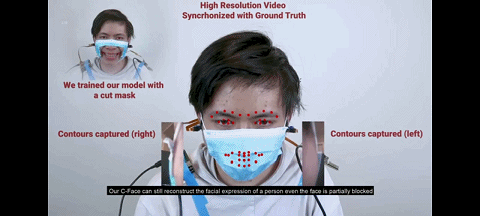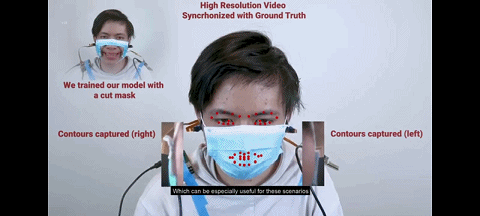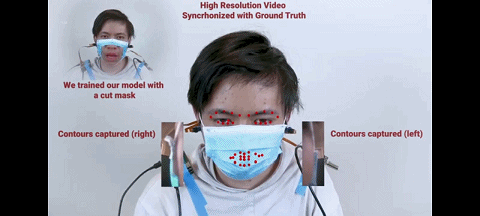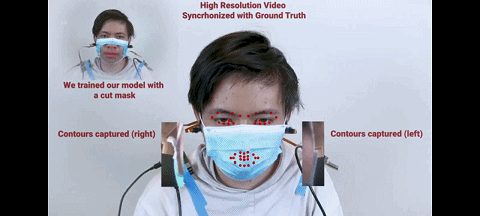
图 戴口罩时戴着耳机做表情
具体来说,耳机内置两个迷你摄像头,它们可以捕捉到侧面脸颊形状,并通过脸颊形状来判断你的脸部表情。因为人在执行面部特征时,面部肌肉组织就会拉伸和收缩,进而推动和拉动毛孔和皮肤,并对面部肌肉组织的紧绷产生影响,这种影响会导致脸颊轮廓发生改变。

图 黑色部分为摄像头
在耳机中,摄像头可以传输数据,数据会传输到微处理器(Raspberry Pi),微处理器收集数据,并把它发到计算机上,这时深度学习算法就能开始工作。
深度学习在耳机中的应用
很多情况下,深度学习在数据上的效果,比传统机器学习的效果更好。本次耳机之要想实现根据侧脸和脸颊形状来推断整个面部表情,其实并不容易,因为每个人的侧脸都不一样。
因此,就得通过深度学习来采集训练数据,具体做法是先采集到用户脸颊变化情况,并结合前置摄像头来捕捉面部表情,以标记出相对应的脸部表情。
这相当于摄像头每一帧图片,都有一个对应的面部表情。采集到训练数据后,研究人员就能发掘出不同脸颊形状与面部表情间的复杂对应关系。

图 训练深度学习
张铖表示,深度学习的好处是能通过复杂学习,来学习一些人类不擅长的技能。有的技能人类很擅长,比如一眼就能识别某些物体。但有些技能人类并不擅长,比如只根据侧面脸颊,我们很难判断出脸部全部形状。
深度学习的能力是,可通过算法找出事物间的复杂联系,从而根据侧部面颊,准确推断出面部表情。
具体工作时,在摄像机捕获图像后,计算机视觉和深度学习模型会对其进行重建。由于原始数据是二维的,因此卷积神经网络(一种擅长对图像进行分类、检测和检索的人工智能模型)有助于将轮廓重构为表达式。
此外,该模型可将脸颊图像转换为 42 个面部特征点,它们分别代表受表情变化影响最大的部位,如嘴巴、眼睛、眉毛等。
这 42 个特征点代表的面部表情,也可用于推测出 8 个表情符号,包括 “无表情”“生气” 和 “ Kissy-face”,另外还有 8 个可用于控制音乐设备的静音语音命令,如 “播放” ,“下一首” 和 “音量增大” 等。
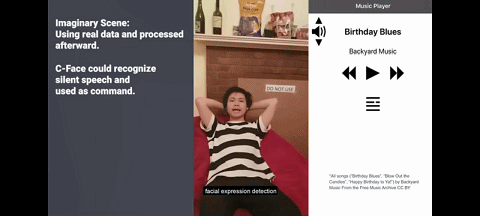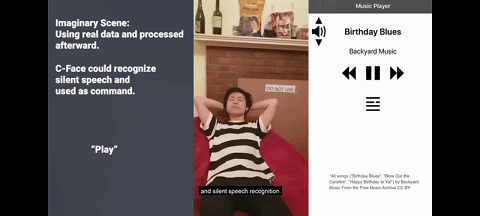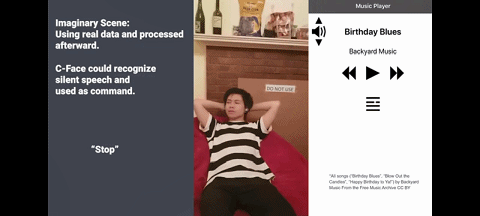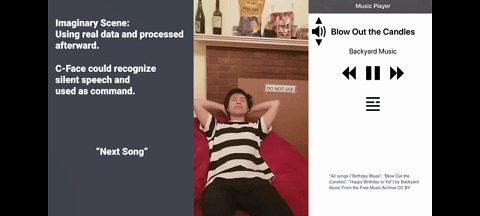
图 静音语音命令
相比传统方法用前置摄像头来识别表情,C-Face 耳机的独特优势是戴着口罩也能被耳机捕捉到表情,即摄像机无需对着人脸,只需观察从耳朵到侧面脸颊的形状就能识别表情。
因为即使你戴着口罩(超大口罩除外),侧面脸颊形状并不会发生巨大改变,这时深度学习仍然可以工作。

图 带上口罩时,深度学习依然可以工作
做个嘴型就能发出指令
本次研究还展示了 C-Face 耳机的两大功能:无声语音识别和前文的输入表情包。
无声语音识别指的是,一般的语音识别,都是通过声音来识别。如果不通过声音,是否也能识别?因为,假如你在开会、看电影等场合,突然说话就会很奇怪。再就是,当周围有很多噪音,即便说话也无法识别。
而 C-Face 耳机可通过分析用户表情,来识别沉默的语音指令。这一功能的常见应用场景有,当你跑步时只需做个嘴形,相关智能设备就能以非常私密的方式,来获悉你的指令。
另一个可以想象的应用场景是健康预测,张铖表示,未来该耳机有望连续记录表情。获得大量表情数据后,就可获知用户每天的心情状况。这样大量的情绪信息,还可帮助计算机了解用户的精神健康状况。
两款耳机:入耳式和头戴式
本次耳机分为两款:入耳式和头戴式,功能上它们非常类似。张铖表示,它们所属项目都叫 C-Face,该项目并不局限于某一种特定的设备,只是在本次论文中展示了入耳式耳机和头戴式耳机。
唯一的区别是,两种耳机的摄像头位置略微不同。头戴耳机相对大一点,有较大空间放摄像头。
谈及耳机是否可用于 VR 游戏,张铖表示,经常有人问他这个问题,而他的答案一直是 Yes or NO。
即当然可以用在 VR 上面,但以他了解到的最新技术来说,VR 眼镜已有更好的解决方案。
VR 眼镜本身已经很大,通过在上面加设备来捕捉人的表情,此前已经有人做过。而 C-Face 耳机的好处是它非常小,日常可以进行穿戴。因此,他觉得 VR 眼镜不一定是 C-Face 耳机最核心的爆点。
他举例称,该实验室的耳机可以潜在地提供视频聊天功能。现在的视频聊天,都需要用户面前放置一个摄像头 (桌子上或者手举着)。
但如果用耳机来聊天,耳机自己就能捕捉你的面部表情,你也不需要把摄像头对着脸,你的朋友时时刻刻都能看到你的脸,包括走路时、开车时、甚至做饭时都可以跟人聊天。
解决功耗问题,就能加速落地
谈及商业落地,张铖表示本次论文发表后,有厂商已经和他们联系讨论一些初步的合作可能性。但想在短期内实现到现有设备,最需要解决的仍然是可穿戴设备上的功耗问题。而这一难题,超出了该实验室的能力,因此需要工业界投入资金去优化功耗问题。
目前的耳机,是研究人员买来零件组装的,摄像头可以选配,只是价钱和分辨率会有区别。在零件的选择上,他们未做过高要求,目的是让设备更快速落地成产品。
他认为,该实验室做这款设备,更多是着眼于未来。他们做研究的目的,更多是描述研究人员眼中的未来可能性。
张铖表示,未来的摄像头可能会变得非常小、功耗也非常低。尽管现在的耳机只是实验室设备,但是如果能耗问题得以解决,它有可能在 5 到 10 年后实现应用。
如果想把小型摄像头利用到现有设备上,能耗是个很大的问题。因为,摄像头会耗电,处理摄像头数据也会耗电,这是该设备的最大局限性。
就落地为产品来说,头戴式耳机短期内可能相对方便一点,因为它可以放置更大的电池。对于入耳式耳机,该实验室未来也会寻找更加低功耗的方法来解决问题。
因为如果把摄像头装在耳机上,那么摄像头的耗电量肯定比耳机多。这种情况下,无论产品有多么酷炫,如果使用十分钟就没电了,也不会有人愿意购买。
如果想快速推出该耳机,可能只能先实现一部分功能,因为工业界做产品都有一个提前周期,比如要想现在发布一款产品,可能两年前就得开始规划。
与此同时,该实验室并不局限于耳机,他们关注的是 “无处不在的计算和人机交互”,未来还有可能研发出智能耳环、智能衣服,而他们的愿望就是让似乎无法智能的物体也变得智能起来。